/is too new to post links, all @ links are github projects
Good stuff!
Despite the ubiquity of the MS format, seeing good jupyter developer effort being thrown at proprietary APIs which can shift out from under our feet (see Google realtime, etc) make me  . See recent “the books will stop working” microsoft DRM thing. Therefore, I’ll dutifully lodge my argument for supporting
. See recent “the books will stop working” microsoft DRM thing. Therefore, I’ll dutifully lodge my argument for supporting .odt (whether .docx is supported or not). .odt readers can run on extremely low-power/cost devices ($5 Raspberry PI zero), the same cannot be said for MSO. Having an open source backbone, such as LibreOffice, would allow the feature to actually be tested in the system-of-interest, as I don’t think there’s any free CI that comes with Word.
On that note, @rossant/ipymd already did a good-enough-to-publish-a-book roundtripping from odt, but the project has languished some, and @podoc/podoc (by the same author) never picked up much steam. Certainly worth a look!
As to the frontend implementation: i also did a rough proof-of-concept on @deathbeds/jupyterlab-outsource.
It needs updating to lab 1.0 (and the binder may be broken as a result).
This came from a @dsblank comment at last JupyterCon that the biggest impediments to a starting-from-scratch student using Jupyter are:
- WYSIWYG text editing (so that can write homework)
- visual discovery of available programming constructs
Ignoring the latter (addressed in outsource by @google/blockly, and a whole other story), the first-pass WYSIWYG approach used @ProseMirror/prosemirror to replace link with the model of the current markdown (actually any) cell. While the bar for working with prosemirror is a little higher than other WYSIWYGs, it’s an extremely rich API.
I got gummed up on trying to embed a CodeMirror inside a Prosemirror, but many revs have passed since then, and it’s definitely worth another look. Initially, that would just be a prose-about-code block, e.g. ``` i think it’s reasonable to assume one could have a markdown-forward UX that allowed you to just start writing text, and choose between literal code and to-be-interpreted code, and have the outputs appear directly in the text, without even worrying about “cells” is just a data model away.
The other Big Deal is $M_{ath}. If/after I got code working, I’d probably take a serious look at @mathquill/mathquill.
Finally, an archival format like PDF/A-2 would be a highly desirable output of spending the effort to make your italics and tables just right. Among other things, PDF/A-2 allows one to store a whole file tree inside the artifact, which means you could stuff your source notebook (and supporting files like sample data) inside the same artifact, sign it, and every PDF viewer will be able to read it.
PDF/A-2 appears to be landing soon in libreoffice:
https://bugs.documentfoundation.org/show_bug.cgi?id=62728.
No doubt one could do this from .docx, but it’s very unlikely most (Linux) servers are going to have a WINE office around. For truly rich things, it may still be necessary to have a (headless) browser in the loop to generate fully-rendered outputs, but QTWebEngine is making this increasingly plausible (see @deathbeds/nbconvert-pdfqt).
Good luck! Happy to discuss further if there’s going to be any public process around this!





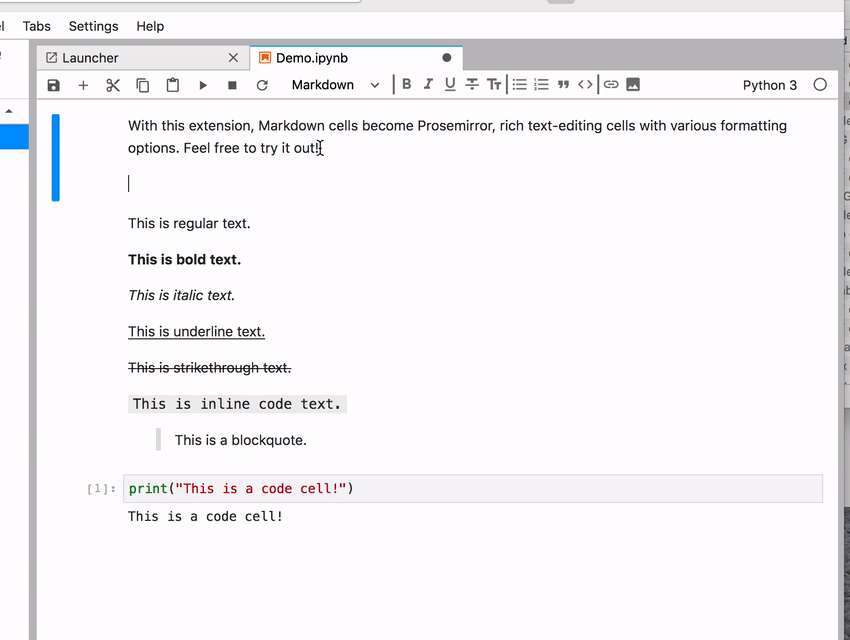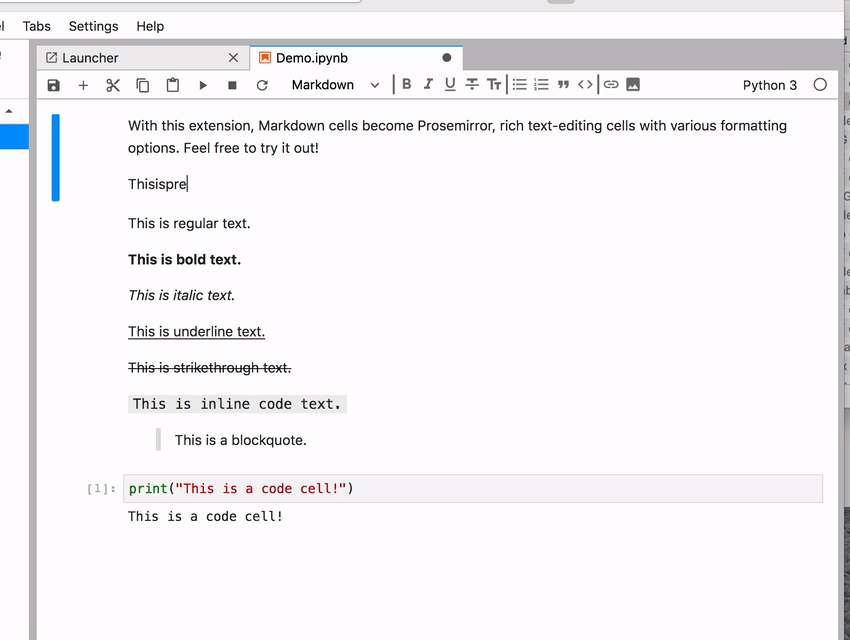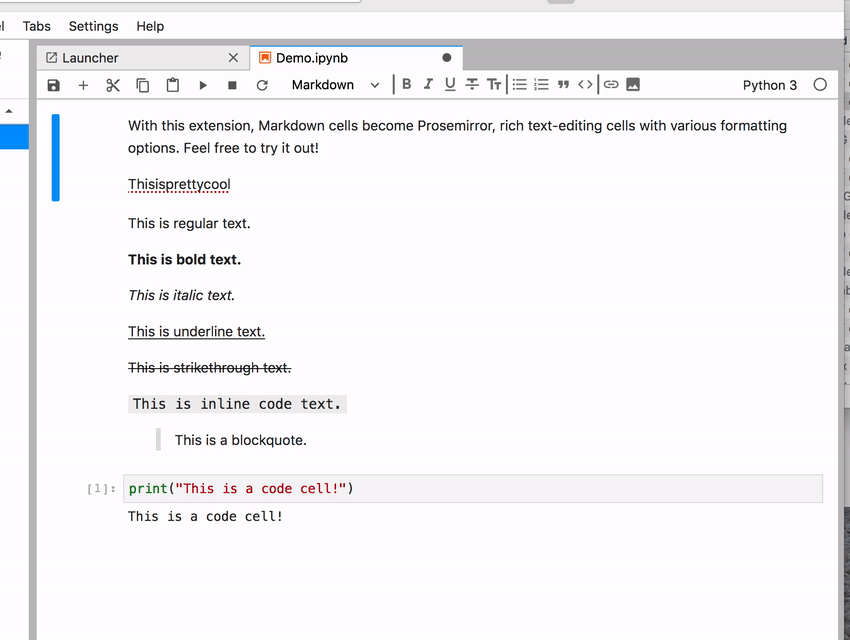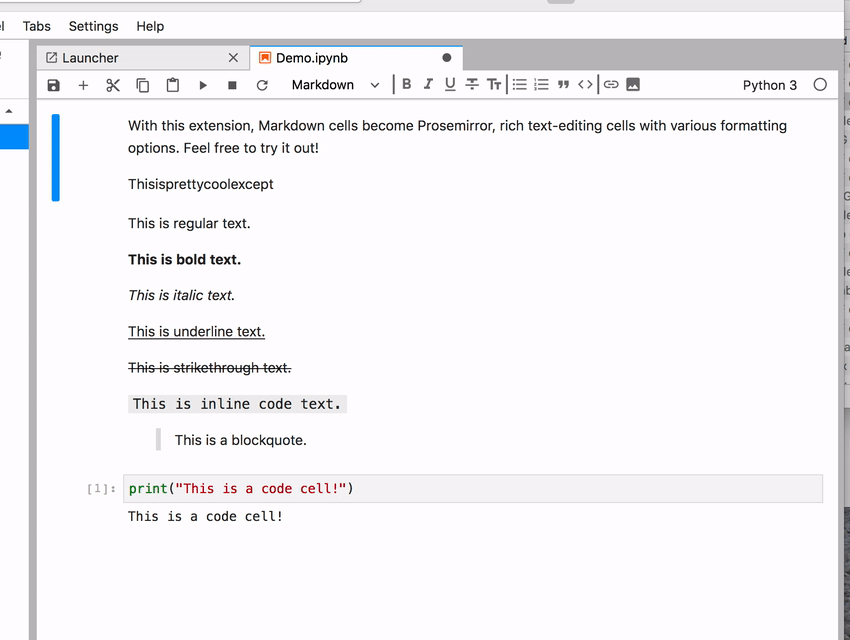
 ! Sometimes the space character gets lost
! Sometimes the space character gets lost  You can’t tell from the recorded GIF but I did press the spacebar at the right places between words. It briefly appears but then gets “eaten” somehow. If you keep typing then sometimes it starts working flawlessly.
You can’t tell from the recorded GIF but I did press the spacebar at the right places between words. It briefly appears but then gets “eaten” somehow. If you keep typing then sometimes it starts working flawlessly.