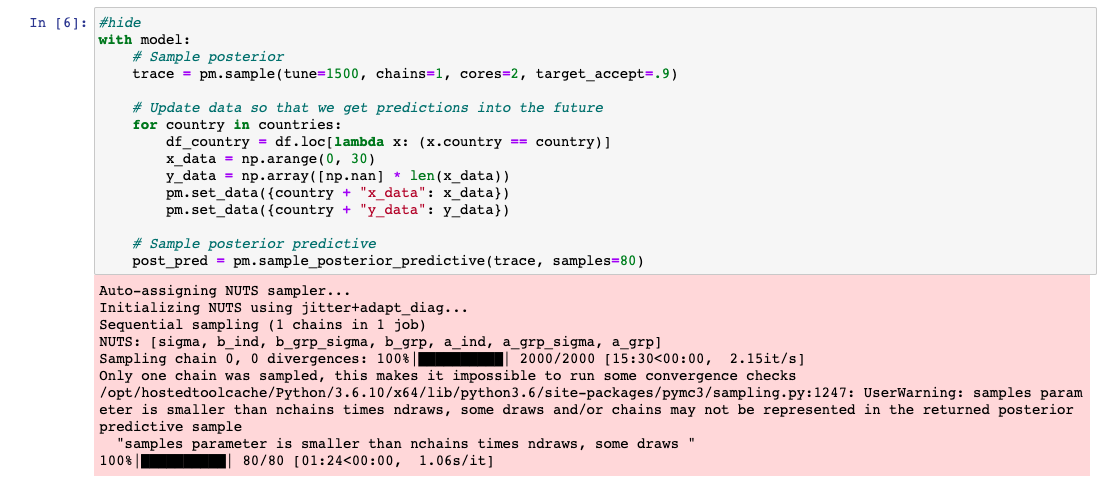
I present an example below where a given cell in the notebook JSON has thousands of stderr outputs (seems like they indicate % of progress of some operation). As soon as I open this notebook in Jupyter, the underlying JSON changes. It -
- removes most of the outputs &
- combines the remaining outputs section into a single output
Can someone please briefly explain (or point me to) the logic of how Jupyter decides which outputs to ignore/remove?
Example
Checkout _notebooks/2020-03-16-covid19_growth_bayes.ipynb in this Pull Request.
You can see the raw JSON here. And here is the rendered version of the same file on nbviewer.
10th cell in this file has thousands of small outputs like shown below,
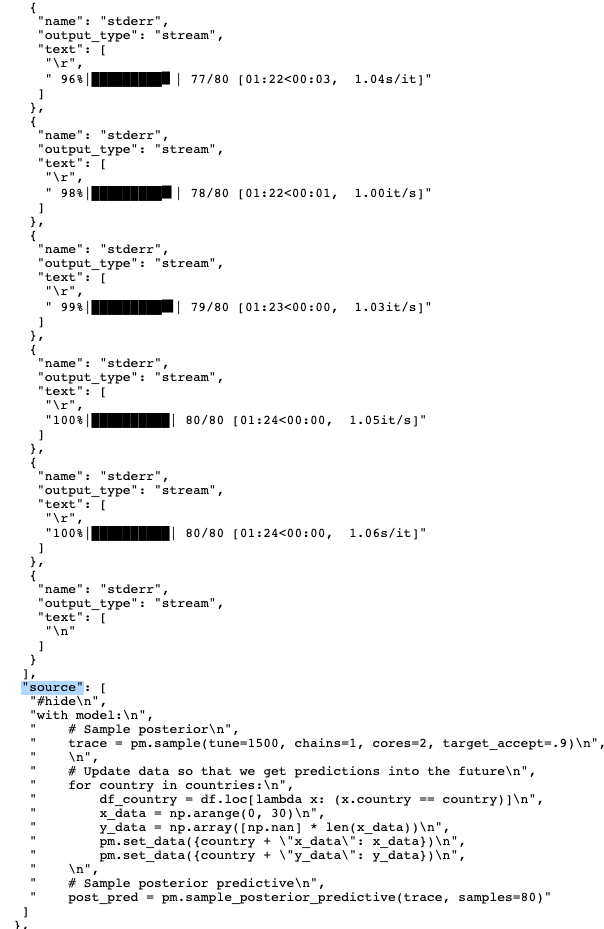
All of those progress bar outputs are removed as soon as you open the file in nbviewer or Jupyter,