I am using API to generate notebook that can be downloaded to JupyterHub. But when I press File->Open from URL and then provide my API URL (like, my.api.com/docs) that returns correct notebook JSON structure. But, I can see content type is file instead of notebook. How the system identifies that this is file or notebook, what should I do to download it as Notebook?
It is more of the JupyterLab question than JupyterHub. I guess JupyterLab detects the mime type based on file extension. Is the extension of the file you are attempting to open .json or .ipynb?
It’s API that returns json it’s not a file .json or .ipynb.
Thanks, changed a category.
Quickly:
- instead of:
http://localhost:8888/api/contents/Untitled.ipynb
- try:
http://localhost:8888/files/Untitled.ipynb
More in-depth:
The GET {:base-url}/api/contents/{:path} API endpoint returns… JSON API responses, as described in the best-effort OpenAPI Spec.
best-effort in that it’s not validated against that spec, per-request, at runtime, and can be changed by extensions
This provides rich metadata one typically wouldn’t get from a typical “dumb” static HTTP endpoint, and critically allows for listing a directory, which is not something HTTP provides by default.
Something missing from the spec is the GET {:base-url}/files/(:path) endpoint, as it’s not really thought of as an API, I suppose: this is an alternate view of the contents that provides traditional HTTP files.
The standards-based play, long term, would indeed be to unify Jupyter Contents with HTTP using an existing standard such as WebDAV RFC 3648… but that’s a lotta XML, and it’s not a W3C or IETF standard. That being said: it is supported by a large number of clients, including most operating systems’ built-in file browsers. And the spec hasn’t changed in 20 years, which is actually a killer feature for a standard.
Thanks, but might I didn’t explain the issue more clearly.
I have my own API that dynamically generate Notebook JSON. So my URL for getting JSON: my.api.com/docs?type=dataframe
What I’m trying to achieve:
I expect as API responses with valid notebook JSON, I will see a downloaded notebook file.
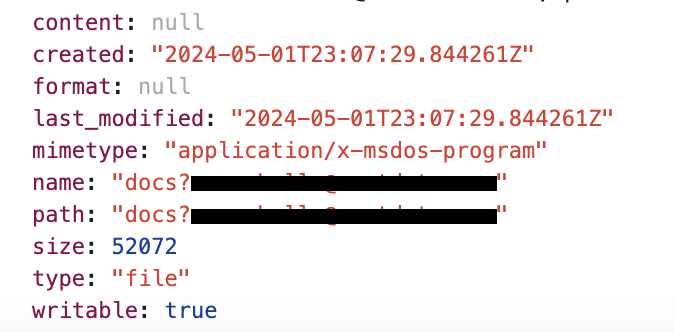
But actually I get a file with name docs?type=dataframe and it’s raw JSON. But if I manually add an extension .ipynb this file is opening as Notebook.
When I’m trying to debug why, I see that my content is downloaded with type file instead of notebook. And I’m trying to understand how system identifies if it’s type file or notebook?
Sorry, without more context, I misunderstood, as that looked like a api/contents response.
Yep: .ipynb is hard-coded to be required in the name of the file (probably ignores the ? params), and without adding another custom Open Random URL And Assume It To Be a Notebook, it’s unlikely to change. So the upstream api would need to be like `/api/{a-useful-file-name}.ipynb?params=get-discarded
Some alternatives (again with almost no context):
- build a
jupyter_server ContentsManager that wraps your API in api/contents (and therefore files/)
- build a client-side lab extension that does one/more of:
- implements that command
- fetch the content as JSON
- create a Contents.IModel
- do something
- fully wrap your API in an
IDrive akin to jupyterlab-github