I’m having trouble understanding how I debug a cluster refusing to schedule on any more than 3 nodes for user pods. Its 3 all the time. At first i thought it was because i asked for 3 placeholders but asking for 5 didnt seem to help. Here are the relevent (i think…) parts of the config.yaml (this on us-east1-c), and I crested the user pool with
gcloud beta container node-pools create jhub-cpu-pool --machine-type n1-standard-2 --num-nodes 1 --enable-autoscaling --min-nodes 1 --max-nodes 34 --node-labels hub.jupyter.org/node-purpose=user --node-taints hub.jupyter.org_dedicated=user:NoSchedule --zone us-east1-c --cluster univai-jhub
prePuller:
continuous:
enabled: true
scheduling:
userScheduler:
enabled: true
podPriority:
enabled: true
userPlaceholder:
enabled: true
replicas: 5
userPods:
nodeAffinity:
matchNodePurpose: require
singleuser:
image:
# Get the latest image tag at:
# https://hub.docker.com/r/jupyter/datascience-notebook/tags/
# Inspect the Dockerfile at:
# https://github.com/jupyter/docker-stacks/tree/master/datascience-notebook/Dockerfile
name: gcr.io/univai-jupyterhub/tensorflow_pytorch_cpu
tag: ae6c90f96f5c025cc66317b27bac8722db7a4097
defaultUrl: "/lab"
storage:
capacity: 4Gi
memory:
guarantee: 1G
limit: 3.5G
cpu:
guarantee: 0.5
limit: 2
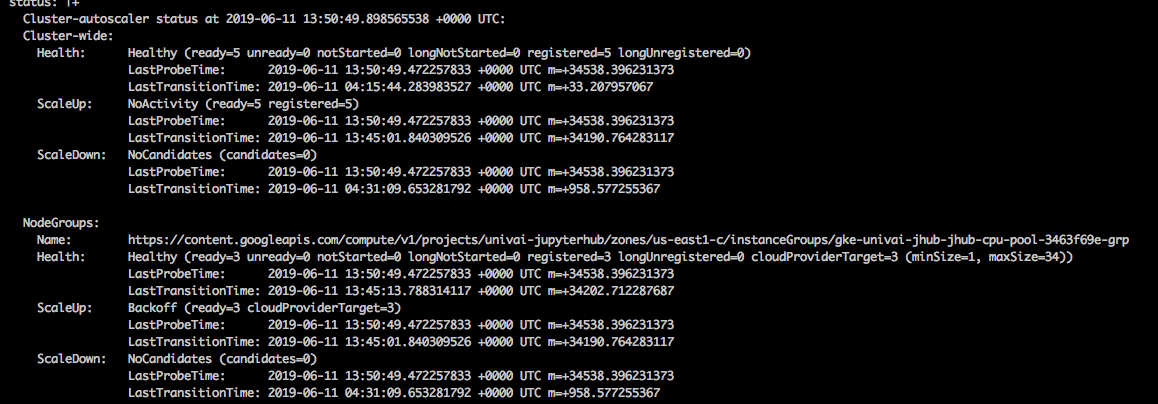
Who ordered the number 3? Its quite peculiar. I thought it was CPU quotas but my quota for CPU(all zones) is 64!
Would appreciate any thoughts on how i might figure whats happening. The error message is

which makes perfect sense since 2 nodes belong to the non-user part of the cluster and wont be scheduled on. The other message seems to reflect the inability of user pods to be scheduled on more than 3 nodes…
EDIT: should add I have one more cluster running in the same GCP project, but its not occupying more than 4 nodes…
Also, how could I artificially add “fake” user pods to debug?