https://tetsing.com/hub/spawn?profile=pydata-stable
https://testing.com/hub/spawn?profile=test-notebook
How to access the two profiles simultaneously and create different prods for each profile.
https://tetsing.com/hub/spawn?profile=pydata-stable
https://testing.com/hub/spawn?profile=test-notebook
How to access the two profiles simultaneously and create different prods for each profile.
You ll have to enabled named servers on your JupyterHub deployment
This is my confilmaps.. After added also multiple profiles not accessing same time with one user.
My requirement is One user can access multiple profiles same time with different pod’s for each profile. How to implement that.
import logging
import requests
logging.getLogger('jupyterhub').setLevel(logging.DEBUG)
# Enable named servers c.JupyterHub.allow_named_servers = True
c.JupyterHub.log_level = 'DEBUG'
# from jupyterhub import authenticator as auth
c.Authenticator.enable_auth_state = True
c = get_config() # noqa
c.ConfigurableHTTPProxy.command = ["configurable-http-proxy",
"--redirect-port=0"]
# Allow your Binder origin to call Hub (CORS)
c.JupyterHub.allow_origin = [
"https://nbhub.eks-miplatform-dev-us-east-1.container.spglobal.com"
]
# Make Hub cookies work in a cross-site flow (strict but safe)
c.JupyterHub.cookie_options = {"SameSite": "None", "Secure": True}
import glob
import os
import re
import sys
from jupyterhub.handlers import BaseHandler
from jupyterhub.utils import url_path_join
from kubernetes_asyncio import client
from tornado.httpclient import AsyncHTTPClient
from tornado.web import HTTPError
from jupyterhub.auth import Authenticator
import os
from urllib.parse import urljoin
class JWTLoginHandler(BaseHandler):
"""
Custom login handler that authenticates using a JWT token
passed in the 'Authorization' header and skips login page.
"""
def get(self):
# Extract the JWT token from Authorization header
# jwt_token = 'Bearer <jwt0 xmlns="http://www.snl.com/security/tokens">eyJ0eXAiOiJKV0UiLCJhbGciOiJSU0ExXzUiLCJ4NXQiOiI0ODI4OUQzRkY2QjcyOENGRTlENjZDOTc2RTk5ODY5RUE1QzZGMTlGIiwiZW5jIjoiQTI1NkNCQyIsIml2IjoiNTJxZE1KQ1RWQlVsYW9qRElGTnl0USIsInppcCI6IlpJUCJ9.TCMS_0tmHamTSUoMHVK2j_RDK7lIhr2R-rKTMaCE2wW4BPx0MtGxmq4b1oahYaBmr6bXqlEmuCQjwTpmMFCofQbJmsltz_5f3KgLjtqT51-6y4oumTX-rTuhYbD1ZwkCnBs5cuxpQ2ezyhG4g9kzrHkMcJ308avj9bGEE3Fb-go.1bnceV1sz-JaIe-FzkEGS6wmPRFoxPHYsEnnWkkfnRlR2KBW1iRnxZww3dtSrXJaMhtId6OAXJJId4kDvdqbPW671VsYGG-VVoVTvk-Ut6LwaJhMyNop0_T7LDLLfZLQ-FML3xe28Sxcjg040plQjJFiW3p7uxYBYExFYzE1_cBZ5L7lhp_Sf-pt_L2HQdq6f1eb05fcAlYndwJnzUijEh3TxKAd2_Sk2h8BT_ZKLJM_g2GwIQnTRjFnbu_M-05kRybXEEhNJJQVJ_guJRhWCRb6UQnkWM2tczPMJPhswwPMH3wxUhAYxzIlpzZKS7KFrLMybPhaeNxv9XEJJH5u_K0Vjv5J9xOPofX9CtJpQNrIXm5njepvEk9Wmof-Bjdy6x39lH998_10LIiq_sF-8v6ZNX2ut-UlAhgPs08trqRlRuMd7vj71dafsPI9V1M5kq7nmsgAxGi6aKfcwg7Dt430NQR10k-u4DAQP8T-aUIQmrn_QmxFmNEVP3CPAr0xmBcUg7kKPzzJIrOnZTHGDAbx5eNbAfqDo_asMG3PEaAT2ErjrIpZMJBVxtg2RMGXEZ3zEPp67YmekYvuQ_k5z6ooBAC5n9S9ppQOryLJ4RzEcSYSE-r5O7QmaALeKFKWAG-k_pWwbH0gX3_kLBgxpkaDaEDyKmtmcCRKnYHOCmTACqMhG-wZ1bCS27e76F99uUyNGyYknKrkoV-j2nFn-mubFOzoVgsEZdh1048fzSIhUX3k0gQYxZss4g0nXBLiU7xUa33ZGqw7REKWkQyTPS35VUWmt1NtFgJhMUaHto4y76AZjTked2p1ZF5FkXMf3segGRapGycwRmKxduVGtHfaZVMR_G_A9Jogc8BmTozaBEoXoHzyZsA3mxjJ7ZHO</jwt0>'
jwt_token = self.request.headers.get('Authorization')
if not jwt_token:
raise HTTPError(401, "Missing Authorization token")
# Call external auth service
auth_url = 'https://www.eks-miplatform-dev-us-east-1.container.spglobal.com/internal/authvalidation-service/claims'
headers = {'Authorization': jwt_token}
try:
response = requests.get(auth_url, headers=headers)
except requests.RequestException as e:
raise HTTPError(500, f"Auth request failed: {e}")
if response.status_code != 200:
raise HTTPError(401, "Invalid token or auth service failed")
try:
claims = response.json()
except json.JSONDecodeError:
raise HTTPError(500, "Invalid JSON response from auth service")
# Extract username from the claims
username = next(
(claim['value'] for claim in claims
if claim['type'] == 'http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name'),
None
)
if not username:
raise HTTPError(401, "Username not found in token claims")
# Create user and set login cookie
user = self.user_from_username(username)
self.set_login_cookie(user)
# spawn_url = urljoin(self.hub.server.base_url,f'spawn?profile={slug}')
spawn_url = self.redirect(urljoin(self.hub.server.base_url, 'spwan'))
# self.redirect(urljoin(self.hub.server.base_url, 'home'))
self.redirect(spawn_url)
class LogoutHandler(BaseHandler):
def get(self):
print("Logout requested")
self.clear_cookie("jupyterhub-session-id", path="/")
self.clear_cookie("jupyterhub-hub-login", path="/hub/")
self.clear_login_cookie() # Clears the login cookie
print("Cleared login cookie")
# Redirect to the hub login page or wherever you want after logout
self.redirect(urljoin(self.hub.server.base_url, 'goodbye'))
class Custom404Handler(BaseHandler):
def prepare(self):
if self.request.path == "/hub/goodbye":
# Set a 404 status with a custom message or template
goodbye_html = """
<!DOCTYPE html>
<html>
<head>
<title>Logged Out</title>
<style>
body { font-family: sans-serif; text-align: center; padding: 3em; background: #f5f5f5; }
h1 { font-size: 2.5em; margin-bottom: 0.5em; }
p { font-size: 1.2em; color: #555; }
a { text-decoration: none; color: #007acc; }
</style>
</head>
<body>
<h1>Goodbye!</h1>
<p>You have been logged out successfully.</p>
<p><a href="/hub/login">Login again</a></p>
</body>
</html>
"""
self.write(goodbye_html)
self.finish()
self.set_status(404)
self.render("goodbye.html", message="You’ve been logged out successfully.")
else:
# Default 404
self.set_status(404)
self.render("404.html", reason="Page not found.")
class LoggedOutHandler(BaseHandler):
def get(self):
self.write("<h2>You have been logged out. Close your browser or <a href='/hub/login'>Login again</a>.</h2>")
class CustomAuthenticator(Authenticator):
"""
Custom authenticator that injects JWTLoginHandler for /login route.
"""
def login_url(self, base_url):
return urljoin(base_url, 'login')
def logout_url(self, base_url):
return urljoin(base_url, 'logout')
def get_handlers(self, app):
return [
('/login', JWTLoginHandler),
('/logout', LogoutHandler),
('/goodbye', Custom404Handler),
]
# def _expand_user_properties(self, template): # ns = { #
'username': self.user.name, # 'servername': self.server_name, #
# Add other properties as needed # }
# # Add this debug line # logging.debug(f"Namespace for pod name
expansion: {ns}")
# # Ensure that `slug` is included in the namespace # if 'slug' not in
ns: # ns['slug'] = self.slug # Ensure slug is set if not already
# try: # rendered = template.format(**ns) # except KeyError as e:
# raise KeyError(f"Missing key in namespace: {e}") # return rendered
# class CustomAuthenticator(Authenticator):
# auth_url
='https://www.eks-miplatform-dev-us-east-1.container.spglobal.com/internal/authvalidation-service/claims'
# def authenticate(self, handler, data): # url = self.auth_url #
#jwt_token = '' # jwt_token = handler.request.headers.get('Authorization')
# if not jwt_token: # print("token issue") # return None
# headers = { # 'Authorization': jwt_token # }
# # headers = { # # 'Cookie': jwt_token # # } #
print("Authentication request sent.") # response = requests.get(url,
headers=headers) # print("Authentication request sent.") #
print("Response JSON:", response.json()) #
print("--------response----------", response.headers.get('Content-Type'))
# if response.status_code == 200: # print("Authentication
successful.") # content_type = response.headers.get('Content-Type',
'') # user_info = response.json() # username =
next((claim['value'] for claim in user_info if claim['type'] ==
'http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name'), None)
# print("Authenticated username-----:", username)
# if username: # print("Authenticated username:", username)
# return { # 'name' : username, #
'auth_state':{ 'claims': user_info } # } # else: #
print("Username not found in the response.") # return None # else:
# print("Authentication failed.") # return None
# Make sure that modules placed in the same directory as the jupyterhub
config are added to the pythonpath
configuration_directory = os.path.dirname(os.path.realpath(__file__))
sys.path.insert(0, configuration_directory)
from z2jh import (
get_config,
get_name,
get_name_env,
get_secret_value,
set_config_if_not_none,
)
def camelCaseify(s):
"""convert snake_case to camelCase
For the common case where some_value is set from someValue
so we don't have to specify the name twice.
"""
return re.sub(r"_([a-z])", lambda m: m.group(1).upper(), s)
# Configure JupyterHub to use the curl backend for making HTTP requests,
# rather than the pure-python implementations. The default one starts
# being too slow to make a large number of requests to the proxy API
# at the rate required.
AsyncHTTPClient.configure("tornado.curl_httpclient.CurlAsyncHTTPClient")
c.JupyterHub.spawner_class = "kubespawner.KubeSpawner"
# Connect to a proxy running in a different pod. Note that *_SERVICE_*
# environment variables are set by Kubernetes for Services
c.ConfigurableHTTPProxy.api_url = (
f'http://{get_name("proxy-api")}:{get_name_env("proxy-api", "_SERVICE_PORT")}'
)
c.ConfigurableHTTPProxy.should_start = False
# Do not shut down user pods when hub is restarted
c.JupyterHub.cleanup_servers = False
# Check that the proxy has routes appropriately setup
c.JupyterHub.last_activity_interval = 60
# Don't wait at all before redirecting a spawning user to the progress page
c.JupyterHub.tornado_settings = {
"slow_spawn_timeout": 0,
}
# configure the hub db connection
db_type = get_config("hub.db.type")
if db_type == "sqlite-pvc":
c.JupyterHub.db_url = "sqlite:///jupyterhub.sqlite"
elif db_type == "sqlite-memory":
c.JupyterHub.db_url = "sqlite://"
else:
set_config_if_not_none(c.JupyterHub, "db_url", "hub.db.url")
db_password = get_secret_value("hub.db.password", None)
if db_password is not None:
if db_type == "mysql":
os.environ["MYSQL_PWD"] = db_password
elif db_type == "postgres":
os.environ["PGPASSWORD"] = db_password
else:
print(f"Warning: hub.db.password is ignored for hub.db.type={db_type}")
# c.JupyterHub configuration from Helm chart's configmap
for trait, cfg_key in (
("concurrent_spawn_limit", None),
("active_server_limit", None),
("base_url", None),
("allow_named_servers", None),
("named_server_limit_per_user", None),
("authenticate_prometheus", None),
("redirect_to_server", None),
("shutdown_on_logout", None),
("template_paths", None),
("template_vars", None),
):
if cfg_key is None:
cfg_key = camelCaseify(trait)
set_config_if_not_none(c.JupyterHub, trait, "hub." + cfg_key)
# hub_bind_url configures what the JupyterHub process within the hub pod's
# container should listen to.
hub_container_port = 8081
c.JupyterHub.hub_bind_url = f"http://:{hub_container_port}"
# hub_connect_url is the URL for connecting to the hub for use by external
# JupyterHub services such as the proxy. Note that *_SERVICE_* environment
# variables are set by Kubernetes for Services.
c.JupyterHub.hub_connect_url = (
f'http://{get_name("hub")}:{get_name_env("hub", "_SERVICE_PORT")}'
)
# implement common labels
# This mimics the jupyterhub.commonLabels helper, but declares managed-by to
# kubespawner instead of helm.
#
# The labels app and release are old labels enabled to be deleted in z2jh 5,
but
# for now retained to avoid a breaking change in z2jh 4 that would force
user
# server restarts. Restarts would be required because NetworkPolicy
resources
# must select old/new pods with labels that then needs to be seen on both
# old/new pods, and we want these resources to keep functioning for old/new
user
# server pods during an upgrade.
#
common_labels = c.KubeSpawner.common_labels = {}
common_labels["app.kubernetes.io/name"] = common_labels["app"] = get_config(
"nameOverride",
default=get_config("Chart.Name", "jupyterhub"),
)
release = get_config("Release.Name")
if release:
common_labels["app.kubernetes.io/instance"] = common_labels["release"] = release
chart_name = get_config("Chart.Name")
chart_version = get_config("Chart.Version")
if chart_name and chart_version:
common_labels["helm.sh/chart"] = common_labels["chart"] = (
f"{chart_name}-{chart_version.replace('+', '_')}"
)
common_labels["app.kubernetes.io/managed-by"] = "kubespawner"
c.KubeSpawner.namespace = os.environ.get("POD_NAMESPACE", "default")
# Max number of consecutive failures before the Hub restarts itself
set_config_if_not_none(
c.Spawner,
"consecutive_failure_limit",
"hub.consecutiveFailureLimit",
)
for trait, cfg_key in (
("pod_name_template", None),
("start_timeout", None),
("image_pull_policy", "image.pullPolicy"),
# ('image_pull_secrets', 'image.pullSecrets'), # Managed manually below
("events_enabled", "events"),
("extra_labels", None),
("extra_annotations", None),
# ("allow_privilege_escalation", None), # Managed manually below
("uid", None),
("fs_gid", None),
("service_account", "serviceAccountName"),
("storage_extra_labels", "storage.extraLabels"),
# ("tolerations", "extraTolerations"), # Managed manually below
("node_selector", None),
("node_affinity_required", "extraNodeAffinity.required"),
("node_affinity_preferred", "extraNodeAffinity.preferred"),
("pod_affinity_required", "extraPodAffinity.required"),
("pod_affinity_preferred", "extraPodAffinity.preferred"),
("pod_anti_affinity_required", "extraPodAntiAffinity.required"),
("pod_anti_affinity_preferred", "extraPodAntiAffinity.preferred"),
("lifecycle_hooks", None),
("init_containers", None),
("extra_containers", None),
("mem_limit", "memory.limit"),
("mem_guarantee", "memory.guarantee"),
("cpu_limit", "cpu.limit"),
("cpu_guarantee", "cpu.guarantee"),
("extra_resource_limits", "extraResource.limits"),
("extra_resource_guarantees", "extraResource.guarantees"),
("environment", "extraEnv"),
("profile_list", None),
("extra_pod_config", None),
):
if cfg_key is None:
cfg_key = camelCaseify(trait)
set_config_if_not_none(c.KubeSpawner, trait, "singleuser." + cfg_key)
image = get_config("singleuser.image.name")
if image:
tag = get_config("singleuser.image.tag")
if tag:
image = f"{image}:{tag}"
c.KubeSpawner.image = image
# allow_privilege_escalation defaults to False in KubeSpawner 2+. Since its
a
# property where None, False, and True all are valid values that users of
the
# Helm chart may want to set, we can't use the set_config_if_not_none helper
# function as someone may want to override the default False value to None.
#
c.KubeSpawner.allow_privilege_escalation = get_config(
"singleuser.allowPrivilegeEscalation"
)
# c.JupyterHub.named_server_limit_per_user = 3 # or whatever
# Combine imagePullSecret.create (single), imagePullSecrets (list), and
# singleuser.image.pullSecrets (list).
image_pull_secrets = []
if get_config("imagePullSecret.automaticReferenceInjection") and get_config(
"imagePullSecret.create"
):
image_pull_secrets.append(get_name("image-pull-secret"))
if get_config("imagePullSecrets"):
image_pull_secrets.extend(get_config("imagePullSecrets"))
if get_config("singleuser.image.pullSecrets"):
image_pull_secrets.extend(get_config("singleuser.image.pullSecrets"))
if image_pull_secrets:
c.KubeSpawner.image_pull_secrets = image_pull_secrets
# scheduling:
if get_config("scheduling.userScheduler.enabled"):
c.KubeSpawner.scheduler_name = get_name("user-scheduler")
if get_config("scheduling.podPriority.enabled"):
c.KubeSpawner.priority_class_name = get_name("priority")
# add node-purpose affinity
match_node_purpose =
get_config("scheduling.userPods.nodeAffinity.matchNodePurpose")
if match_node_purpose:
node_selector = dict(
matchExpressions=[
dict(
key="hub.jupyter.org/node-purpose",
operator="In",
values=["user"],
)
],
)
if match_node_purpose == "prefer":
c.KubeSpawner.node_affinity_preferred.append(
dict(
weight=100,
preference=node_selector,
),
)
elif match_node_purpose == "require":
c.KubeSpawner.node_affinity_required.append(node_selector)
elif match_node_purpose == "ignore":
pass
else:
raise ValueError(
f"Unrecognized value for matchNodePurpose: {match_node_purpose}"
)
# Combine the common tolerations for user pods with singleuser tolerations
scheduling_user_pods_tolerations =
get_config("scheduling.userPods.tolerations", [])
singleuser_extra_tolerations = get_config("singleuser.extraTolerations", [])
tolerations = scheduling_user_pods_tolerations +
singleuser_extra_tolerations
if tolerations:
c.KubeSpawner.tolerations = tolerations
# Configure dynamically provisioning pvc
storage_type = get_config("singleuser.storage.type")
if storage_type == "dynamic":
pvc_name_template = get_config("singleuser.storage.dynamic.pvcNameTemplate")
if pvc_name_template:
c.KubeSpawner.pvc_name_template = pvc_name_template
volume_name_template = get_config("singleuser.storage.dynamic.volumeNameTemplate")
c.KubeSpawner.storage_pvc_ensure = True
set_config_if_not_none(
c.KubeSpawner, "storage_class", "singleuser.storage.dynamic.storageClass"
)
set_config_if_not_none(
c.KubeSpawner,
"storage_access_modes",
"singleuser.storage.dynamic.storageAccessModes",
)
set_config_if_not_none(
c.KubeSpawner, "storage_capacity", "singleuser.storage.capacity"
)
# Add volumes to singleuser pods
c.KubeSpawner.volumes = [
{
"name": volume_name_template,
"persistentVolumeClaim": {"claimName": "{pvc_name}"},
}
]
c.KubeSpawner.volume_mounts = [
{
"mountPath": get_config("singleuser.storage.homeMountPath"),
"name": volume_name_template,
"subPath": get_config("singleuser.storage.dynamic.subPath"),
}
]
elif storage_type == "static":
pvc_claim_name = get_config("singleuser.storage.static.pvcName")
c.KubeSpawner.volumes = [
{"name": "home", "persistentVolumeClaim": {"claimName": pvc_claim_name}}
]
c.KubeSpawner.volume_mounts = [
{
"mountPath": get_config("singleuser.storage.homeMountPath"),
"name": "home",
"subPath": get_config("singleuser.storage.static.subPath"),
}
]
# Inject singleuser.extraFiles as volumes and volumeMounts with data loaded
from
# the dedicated k8s Secret prepared to hold the extraFiles actual content.
extra_files = get_config("singleuser.extraFiles", {})
if extra_files:
volume = {
"name": "files",
}
items = []
for file_key, file_details in extra_files.items():
# Each item is a mapping of a key in the k8s Secret to a path in this
# abstract volume, the goal is to enable us to set the mode /
# permissions only though so we don't change the mapping.
item = {
"key": file_key,
"path": file_key,
}
if "mode" in file_details:
item["mode"] = file_details["mode"]
items.append(item)
volume["secret"] = {
"secretName": get_name("singleuser"),
"items": items,
}
c.KubeSpawner.volumes.append(volume)
volume_mounts = []
for file_key, file_details in extra_files.items():
volume_mounts.append(
{
"mountPath": file_details["mountPath"],
"subPath": file_key,
"name": "files",
}
)
c.KubeSpawner.volume_mounts.extend(volume_mounts)
# Inject extraVolumes / extraVolumeMounts
c.KubeSpawner.volumes.extend(get_config("singleuser.storage.extraVolumes",
[]))
c.KubeSpawner.volume_mounts.extend(
get_config("singleuser.storage.extraVolumeMounts", [])
)
c.JupyterHub.services = []
c.JupyterHub.load_roles = []
# jupyterhub-idle-culler's permissions are scoped to what it needs only, see
# https://github.com/jupyterhub/jupyterhub-idle-culler#permissions.
#
if get_config("cull.enabled", False):
jupyterhub_idle_culler_role = {
"name": "jupyterhub-idle-culler",
"scopes": [
"list:users",
"read:users:activity",
"read:servers",
"delete:servers",
# "admin:users", # dynamically added if --cull-users is passed
],
# assign the role to a jupyterhub service, so it gains these permissions
"services": ["jupyterhub-idle-culler"],
}
cull_cmd = ["python3", "-m", "jupyterhub_idle_culler"]
base_url = c.JupyterHub.get("base_url", "/")
cull_cmd.append("--url=http://localhost:8081" + url_path_join(base_url, "hub/api"))
cull_timeout = get_config("cull.timeout")
if cull_timeout:
cull_cmd.append(f"--timeout={cull_timeout}")
cull_every = get_config("cull.every")
if cull_every:
cull_cmd.append(f"--cull-every={cull_every}")
cull_concurrency = get_config("cull.concurrency")
if cull_concurrency:
cull_cmd.append(f"--concurrency={cull_concurrency}")
if get_config("cull.users"):
cull_cmd.append("--cull-users")
jupyterhub_idle_culler_role["scopes"].append("admin:users")
if not get_config("cull.adminUsers"):
cull_cmd.append("--cull-admin-users=false")
if get_config("cull.removeNamedServers"):
cull_cmd.append("--remove-named-servers")
cull_max_age = get_config("cull.maxAge")
if cull_max_age:
cull_cmd.append(f"--max-age={cull_max_age}")
c.JupyterHub.services.append(
{
"name": "jupyterhub-idle-culler",
"command": cull_cmd,
}
)
c.JupyterHub.load_roles.append(jupyterhub_idle_culler_role)
for key, service in get_config("hub.services", {}).items():
# c.JupyterHub.services is a list of dicts, but
# hub.services is a dict of dicts to make the config mergable
service.setdefault("name", key)
# As the api_token could be exposed in hub.existingSecret, we need to read
# it it from there or fall back to the chart managed k8s Secret's value.
service.pop("apiToken", None)
service["api_token"] = get_secret_value(f"hub.services.{key}.apiToken")
c.JupyterHub.services.append(service)
for key, role in get_config("hub.loadRoles", {}).items():
# c.JupyterHub.load_roles is a list of dicts, but
# hub.loadRoles is a dict of dicts to make the config mergable
role.setdefault("name", key)
c.JupyterHub.load_roles.append(role)
# respect explicit null command (distinct from unspecified)
# this avoids relying on KubeSpawner.cmd's default being None
_unspecified = object()
specified_cmd = get_config("singleuser.cmd", _unspecified)
if specified_cmd is not _unspecified:
c.Spawner.cmd = specified_cmd
set_config_if_not_none(c.Spawner, "default_url", "singleuser.defaultUrl")
# --- Option A: Profiles (prebuilt images)
------------------------------------
# Landing page inside the user container
# c.Spawner.default_url = "/lab" # or "/tree" if you prefer classic
Notebook c.JupyterHub.redirect_to_server = True c.JupyterHub.default_url =
'/lab' # If you need a dockerconfigjson pull secret instead of IRSA,
uncomment:
# c.KubeSpawner.image_pull_secrets = ["ecr-dockerconfigjson"]
# One profile per image. "slug" becomes the query param for one-click links.
c.KubeSpawner.profile_list = [
{
"display_name": "Test-Notebook",
"slug": "pydata-stable",
"description": "Python data stack (numpy, pandas, matplotlib, sklearn)",
"kubespawner_override": {
"image": "test-1",
"cmd": ["jupyterhub-singleuser"],
"image_pull_policy": "IfNotPresent",
"cpu_limit": 2,
"mem_limit": "2G",
# optional: env, nodeSelector, tolerations, etc.
"environment": {"JUPYTER_ENABLE_LAB": "yes",},
},
},
{
"display_name": "Anothr-Test-Notebook",
"slug": "pydata-stable",
"description": "Local image",
"kubespawner_override": {
"image": "test_2",
"image_pull_policy": "IfNotPresent",
"cpu_limit": 2,
"mem_limit": "2G",
},
},
{
"display_name": "R Stats",
"slug": "r-stats",
"description": "R + tidyverse + IRkernel",
"kubespawner_override": {
"image": "123456789012.dkr.ecr.us-east-1.amazonaws.com/rstats:latest",
"image_pull_policy": "IfNotPresent",
"cpu_limit": 2,
"mem_limit": "4G",
},
},
{
"display_name": "GPU PyTorch",
"slug": "pytorch-gpu",
"description": "PyTorch + CUDA (requires GPU nodes)",
"kubespawner_override": {
"image": "123456789012.dkr.ecr.us-east-1.amazonaws.com/pytorch-gpu:2.4-cuda",
"image_pull_policy": "IfNotPresent",
"cpu_limit": 4,
"mem_limit": "16G",
"extra_resource_limits": {"nvidia.com/gpu": "1"},
},
},
]
#
-----------------------------------------------------------------------------
cloud_metadata = get_config("singleuser.cloudMetadata")
if cloud_metadata.get("blockWithIptables") == True:
# Use iptables to block access to cloud metadata by default
network_tools_image_name = get_config("singleuser.networkTools.image.name")
network_tools_image_tag = get_config("singleuser.networkTools.image.tag")
network_tools_resources = get_config("singleuser.networkTools.resources")
ip = cloud_metadata["ip"]
ip_block_container = client.V1Container(
name="block-cloud-metadata",
image=f"{network_tools_image_name}:{network_tools_image_tag}",
command=[
"iptables",
"--append",
"OUTPUT",
"--protocol",
"tcp",
"--destination",
ip,
"--destination-port",
"80",
"--jump",
"DROP",
],
security_context=client.V1SecurityContext(
privileged=True,
run_as_user=0,
capabilities=client.V1Capabilities(add=["NET_ADMIN"]),
),
resources=network_tools_resources,
)
c.KubeSpawner.init_containers.append(ip_block_container)
if get_config("debug.enabled", False):
c.JupyterHub.log_level = "DEBUG"
c.Spawner.debug = True
# load potentially seeded secrets
#
# NOTE: ConfigurableHTTPProxy.auth_token is set through an environment
variable
# that is set using the chart managed secret.
c.JupyterHub.cookie_secret =
get_secret_value("hub.config.JupyterHub.cookie_secret")
# NOTE: CryptKeeper.keys should be a list of strings, but we have encoded as
a
# single string joined with ; in the k8s Secret.
#
c.CryptKeeper.keys =
get_secret_value("hub.config.CryptKeeper.keys").split(";")
# load hub.config values, except potentially seeded secrets already loaded
for app, cfg in get_config("hub.config", {}).items():
if app == "JupyterHub":
cfg.pop("proxy_auth_token", None)
cfg.pop("cookie_secret", None)
cfg.pop("services", None)
elif app == "ConfigurableHTTPProxy":
cfg.pop("auth_token", None)
elif app == "CryptKeeper":
cfg.pop("keys", None)
c[app].update(cfg)
# load /usr/local/etc/jupyterhub/jupyterhub_config.d config files
config_dir = "/usr/local/etc/jupyterhub/jupyterhub_config.d"
if os.path.isdir(config_dir):
for file_path in sorted(glob.glob(f"{config_dir}/*.py")):
file_name = os.path.basename(file_path)
print(f"Loading {config_dir} config: {file_name}")
with open(file_path) as f:
file_content = f.read()
# compiling makes debugging easier: https://stackoverflow.com/a/437857
exec(compile(source=file_content, filename=file_name, mode="exec"))
# execute hub.extraConfig entries
for key, config_py in sorted(get_config("hub.extraConfig", {}).items()):
print(f"Loading extra config: {key}")
exec(config_py)
print("Final auth config override - maximum permissive")
# sys.path.append('/usr/local/bin')
c.JupyterHub.authenticator_class = CustomAuthenticator
# c.JupyterHub.authenticator_class = 'jupyterhub.auth.DummyAuthenticator'
# #c.Authenticator.allowed_users = {"s.kandimalla@spglobal.com"}
# c.DummyAuthenticator.password = '' # Empty password
# c.Authenticator.allow_all = True
# c.Authenticator.allowed_users = set()
# c.Authenticator.admin_users = set() # Clear admin users requirement
# c.Authenticator.blocked_users = set() # Clear any blocked users
# Disable all restrictions
c.JupyterHub.tornado_settings.update({"xsrf_cookies": False})
c.JupyterHub.spawner_class = "kubespawner.KubeSpawner"
# Fix 1: Disable cloud metadata blocking (uses public quay.io image)
c.KubeSpawner.init_containers = [] # Remove the problematic init container
# Fix 2: Set required resource limits/requests for quota compliance
c.KubeSpawner.cpu_limit = 1
c.KubeSpawner.mem_limit = "1G"
c.KubeSpawner.cpu_guarantee = 0.1 # Same as requests.cpu
c.KubeSpawner.mem_guarantee = "512M" # Same as requests.memory
This does not look good. The config is embedded into the comment. Please check the file and move it into new line.
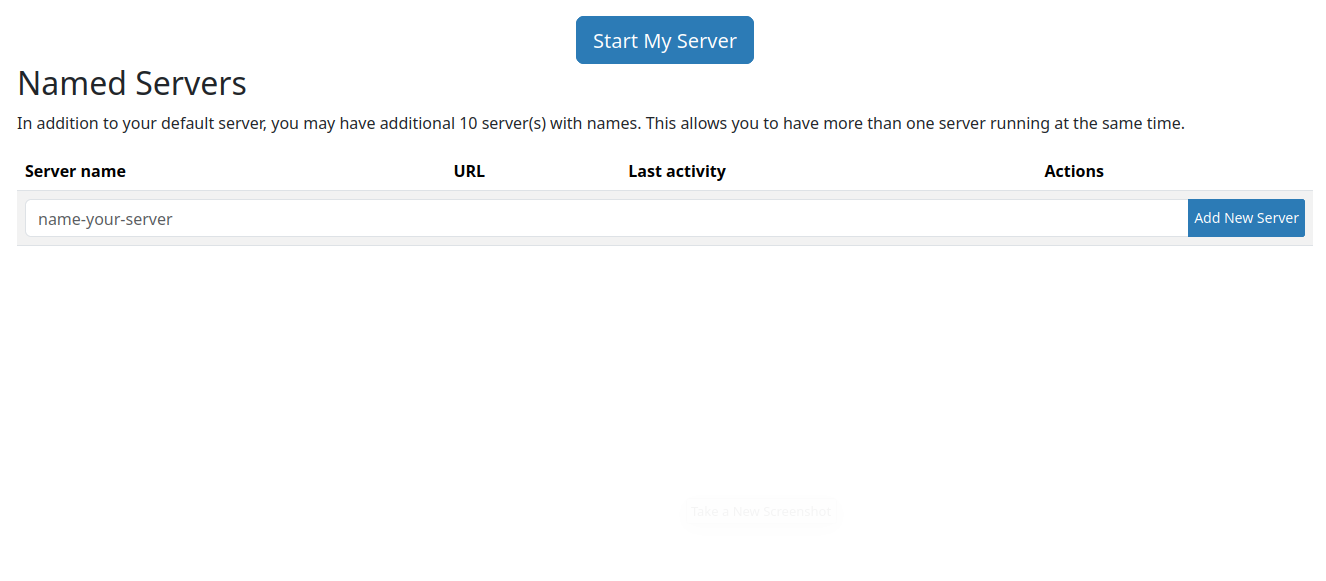
Once named servers are enabled, you will see the following page when you log into Hub:
There you can create more than one server by giving it a name and access different profiles at the same time
Even If I remove the commented line also still redirecting the previous which is already open . Not redirecting the another one. Any more changes required other than this. Because only one Pod only getting generating. Each profile can have one pod, if user accessing multiple profiles can have more pods ?
import logging
import requests
logging.getLogger('jupyterhub').setLevel(logging.DEBUG)
# Enable named servers
c.JupyterHub.allow_named_servers = True
c.JupyterHub.log_level = 'DEBUG'
# from jupyterhub import authenticator as auth
c.Authenticator.enable_auth_state = True
c = get_config() # noqa
c.ConfigurableHTTPProxy.command = ["configurable-http-proxy",
"--redirect-port=0"]
# Allow your Binder origin to call Hub (CORS)
c.JupyterHub.allow_origin = [
"https://nbhub.eks-miplatform-dev-us-east-1.container.spglobal.com"
]
# Make Hub cookies work in a cross-site flow (strict but safe)
c.JupyterHub.cookie_options = {"SameSite": "None", "Secure": True}
import glob
import os
import re
import sys
from jupyterhub.handlers import BaseHandler
from jupyterhub.utils import url_path_join
from kubernetes_asyncio import client
from tornado.httpclient import AsyncHTTPClient
from tornado.web import HTTPError
from jupyterhub.auth import Authenticator
import os
from urllib.parse import urljoin
class JWTLoginHandler(BaseHandler):
"""
Custom login handler that authenticates using a JWT token
passed in the 'Authorization' header and skips login page.
"""
def get(self):
jwt_token = self.request.headers.get('Authorization')
if not jwt_token:
raise HTTPError(401, "Missing Authorization token")
# Call external auth service
auth_url = 'test.com'
headers = {'Authorization': jwt_token}
try:
response = requests.get(auth_url, headers=headers)
except requests.RequestException as e:
raise HTTPError(500, f"Auth request failed: {e}")
if response.status_code != 200:
raise HTTPError(401, "Invalid token or auth service failed")
try:
claims = response.json()
except json.JSONDecodeError:
raise HTTPError(500, "Invalid JSON response from auth service")
# Extract username from the claims
username = next(
(claim['value'] for claim in claims
if claim['type'] == 'http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name'),
None
)
if not username:
raise HTTPError(401, "Username not found in token claims")
# Create user and set login cookie
user = self.user_from_username(username)
self.set_login_cookie(user)
spawn_url = urljoin(self.hub.server.base_url,f'spawn?profile={slug}')
# spawn_url = self.redirect(urljoin(self.hub.server.base_url, 'spwan'))
# self.redirect(urljoin(self.hub.server.base_url, 'home'))
self.redirect(spawn_url)
class LogoutHandler(BaseHandler):
def get(self):
print("Logout requested")
self.clear_cookie("jupyterhub-session-id", path="/")
self.clear_cookie("jupyterhub-hub-login", path="/hub/")
self.clear_login_cookie() # Clears the login cookie
print("Cleared login cookie")
# Redirect to the hub login page or wherever you want after logout
self.redirect(urljoin(self.hub.server.base_url, 'goodbye'))
class Custom404Handler(BaseHandler):
def prepare(self):
if self.request.path == "/hub/goodbye":
# Set a 404 status with a custom message or template
goodbye_html = """
<!DOCTYPE html>
<html>
<head>
<title>Logged Out</title>
<style>
body { font-family: sans-serif; text-align: center; padding: 3em; background: #f5f5f5; }
h1 { font-size: 2.5em; margin-bottom: 0.5em; }
p { font-size: 1.2em; color: #555; }
a { text-decoration: none; color: #007acc; }
</style>
</head>
<body>
<h1>Goodbye!</h1>
<p>You have been logged out successfully.</p>
<p><a href="/hub/login">Login again</a></p>
</body>
</html>
"""
self.write(goodbye_html)
self.finish()
self.set_status(404)
self.render("goodbye.html", message="You’ve been logged out successfully.")
else:
# Default 404
self.set_status(404)
self.render("404.html", reason="Page not found.")
class LoggedOutHandler(BaseHandler):
def get(self):
self.write("<h2>You have been logged out. Close your browser or <a href='/hub/login'>Login again</a>.</h2>")
class CustomAuthenticator(Authenticator):
"""
Custom authenticator that injects JWTLoginHandler for /login route.
"""
def login_url(self, base_url):
return urljoin(base_url, 'login')
def logout_url(self, base_url):
return urljoin(base_url, 'logout')
def get_handlers(self, app):
return [
('/login', JWTLoginHandler),
('/logout', LogoutHandler),
('/goodbye', Custom404Handler),
]
# def _expand_user_properties(self, template): # ns = { #
'username': self.user.name, # 'servername': self.server_name, #
# Add other properties as needed # }
# # Add this debug line # logging.debug(f"Namespace for pod name
expansion: {ns}")
# # Ensure that `slug` is included in the namespace # if 'slug' not in
ns: # ns['slug'] = self.slug # Ensure slug is set if not already
# try: # rendered = template.format(**ns) # except KeyError as e:
# raise KeyError(f"Missing key in namespace: {e}") # return rendered
# class CustomAuthenticator(Authenticator):
# auth_url
='https://www.eks-miplatform-dev-us-east-1.container.spglobal.com/internal/authvalidation-service/claims'
# def authenticate(self, handler, data): # url = self.auth_url #
#jwt_token = '' # jwt_token = handler.request.headers.get('Authorization')
# if not jwt_token: # print("token issue") # return None
# headers = { # 'Authorization': jwt_token # }
# # headers = { # # 'Cookie': jwt_token # # } #
print("Authentication request sent.") # response = requests.get(url,
headers=headers) # print("Authentication request sent.") #
print("Response JSON:", response.json()) #
print("--------response----------", response.headers.get('Content-Type'))
# if response.status_code == 200: # print("Authentication
successful.") # content_type = response.headers.get('Content-Type',
'') # user_info = response.json() # username =
next((claim['value'] for claim in user_info if claim['type'] ==
'http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name'), None)
# print("Authenticated username-----:", username)
# if username: # print("Authenticated username:", username)
# return { # 'name' : username, #
'auth_state':{ 'claims': user_info } # } # else: #
print("Username not found in the response.") # return None # else:
# print("Authentication failed.") # return None
# Make sure that modules placed in the same directory as the jupyterhub
config are added to the pythonpath
configuration_directory = os.path.dirname(os.path.realpath(__file__))
sys.path.insert(0, configuration_directory)
from z2jh import (
get_config,
get_name,
get_name_env,
get_secret_value,
set_config_if_not_none,
)
def camelCaseify(s):
"""convert snake_case to camelCase
For the common case where some_value is set from someValue
so we don't have to specify the name twice.
"""
return re.sub(r"_([a-z])", lambda m: m.group(1).upper(), s)
# Configure JupyterHub to use the curl backend for making HTTP requests,
# rather than the pure-python implementations. The default one starts
# being too slow to make a large number of requests to the proxy API
# at the rate required.
AsyncHTTPClient.configure("tornado.curl_httpclient.CurlAsyncHTTPClient")
c.JupyterHub.spawner_class = "kubespawner.KubeSpawner"
# Connect to a proxy running in a different pod. Note that *_SERVICE_*
# environment variables are set by Kubernetes for Services
c.ConfigurableHTTPProxy.api_url = (
f'http://{get_name("proxy-api")}:{get_name_env("proxy-api", "_SERVICE_PORT")}'
)
c.ConfigurableHTTPProxy.should_start = False
# Do not shut down user pods when hub is restarted
c.JupyterHub.cleanup_servers = False
# Check that the proxy has routes appropriately setup
c.JupyterHub.last_activity_interval = 60
# Don't wait at all before redirecting a spawning user to the progress page
c.JupyterHub.tornado_settings = {
"slow_spawn_timeout": 0,
}
# configure the hub db connection
db_type = get_config("hub.db.type")
if db_type == "sqlite-pvc":
c.JupyterHub.db_url = "sqlite:///jupyterhub.sqlite"
elif db_type == "sqlite-memory":
c.JupyterHub.db_url = "sqlite://"
else:
set_config_if_not_none(c.JupyterHub, "db_url", "hub.db.url")
db_password = get_secret_value("hub.db.password", None)
if db_password is not None:
if db_type == "mysql":
os.environ["MYSQL_PWD"] = db_password
elif db_type == "postgres":
os.environ["PGPASSWORD"] = db_password
else:
print(f"Warning: hub.db.password is ignored for hub.db.type={db_type}")
# c.JupyterHub configuration from Helm chart's configmap
for trait, cfg_key in (
("concurrent_spawn_limit", None),
("active_server_limit", None),
("base_url", None),
("allow_named_servers", None),
("named_server_limit_per_user", None),
("authenticate_prometheus", None),
("redirect_to_server", None),
("shutdown_on_logout", None),
("template_paths", None),
("template_vars", None),
):
if cfg_key is None:
cfg_key = camelCaseify(trait)
set_config_if_not_none(c.JupyterHub, trait, "hub." + cfg_key)
# hub_bind_url configures what the JupyterHub process within the hub pod's
# container should listen to.
hub_container_port = 8081
c.JupyterHub.hub_bind_url = f"http://:{hub_container_port}"
# hub_connect_url is the URL for connecting to the hub for use by external
# JupyterHub services such as the proxy. Note that *_SERVICE_* environment
# variables are set by Kubernetes for Services.
c.JupyterHub.hub_connect_url = (
f'http://{get_name("hub")}:{get_name_env("hub", "_SERVICE_PORT")}'
)
# implement common labels
# This mimics the jupyterhub.commonLabels helper, but declares managed-by to
# kubespawner instead of helm.
#
# The labels app and release are old labels enabled to be deleted in z2jh 5,
but
# for now retained to avoid a breaking change in z2jh 4 that would force
user
# server restarts. Restarts would be required because NetworkPolicy
resources
# must select old/new pods with labels that then needs to be seen on both
# old/new pods, and we want these resources to keep functioning for old/new
user
# server pods during an upgrade.
#
common_labels = c.KubeSpawner.common_labels = {}
common_labels["app.kubernetes.io/name"] = common_labels["app"] = get_config(
"nameOverride",
default=get_config("Chart.Name", "jupyterhub"),
)
release = get_config("Release.Name")
if release:
common_labels["app.kubernetes.io/instance"] = common_labels["release"] = release
chart_name = get_config("Chart.Name")
chart_version = get_config("Chart.Version")
if chart_name and chart_version:
common_labels["helm.sh/chart"] = common_labels["chart"] = (
f"{chart_name}-{chart_version.replace('+', '_')}"
)
common_labels["app.kubernetes.io/managed-by"] = "kubespawner"
c.KubeSpawner.namespace = os.environ.get("POD_NAMESPACE", "default")
# Max number of consecutive failures before the Hub restarts itself
set_config_if_not_none(
c.Spawner,
"consecutive_failure_limit",
"hub.consecutiveFailureLimit",
)
for trait, cfg_key in (
("pod_name_template", None),
("start_timeout", None),
("image_pull_policy", "image.pullPolicy"),
# ('image_pull_secrets', 'image.pullSecrets'), # Managed manually below
("events_enabled", "events"),
("extra_labels", None),
("extra_annotations", None),
# ("allow_privilege_escalation", None), # Managed manually below
("uid", None),
("fs_gid", None),
("service_account", "serviceAccountName"),
("storage_extra_labels", "storage.extraLabels"),
# ("tolerations", "extraTolerations"), # Managed manually below
("node_selector", None),
("node_affinity_required", "extraNodeAffinity.required"),
("node_affinity_preferred", "extraNodeAffinity.preferred"),
("pod_affinity_required", "extraPodAffinity.required"),
("pod_affinity_preferred", "extraPodAffinity.preferred"),
("pod_anti_affinity_required", "extraPodAntiAffinity.required"),
("pod_anti_affinity_preferred", "extraPodAntiAffinity.preferred"),
("lifecycle_hooks", None),
("init_containers", None),
("extra_containers", None),
("mem_limit", "memory.limit"),
("mem_guarantee", "memory.guarantee"),
("cpu_limit", "cpu.limit"),
("cpu_guarantee", "cpu.guarantee"),
("extra_resource_limits", "extraResource.limits"),
("extra_resource_guarantees", "extraResource.guarantees"),
("environment", "extraEnv"),
("profile_list", None),
("extra_pod_config", None),
):
if cfg_key is None:
cfg_key = camelCaseify(trait)
set_config_if_not_none(c.KubeSpawner, trait, "singleuser." + cfg_key)
image = get_config("singleuser.image.name")
if image:
tag = get_config("singleuser.image.tag")
if tag:
image = f"{image}:{tag}"
c.KubeSpawner.image = image
# allow_privilege_escalation defaults to False in KubeSpawner 2+. Since its
a
# property where None, False, and True all are valid values that users of
the
# Helm chart may want to set, we can't use the set_config_if_not_none helper
# function as someone may want to override the default False value to None.
#
c.KubeSpawner.allow_privilege_escalation = get_config(
"singleuser.allowPrivilegeEscalation"
)
# Combine imagePullSecret.create (single), imagePullSecrets (list), and
# singleuser.image.pullSecrets (list).
image_pull_secrets = []
if get_config("imagePullSecret.automaticReferenceInjection") and get_config(
"imagePullSecret.create"
):
image_pull_secrets.append(get_name("image-pull-secret"))
if get_config("imagePullSecrets"):
image_pull_secrets.extend(get_config("imagePullSecrets"))
if get_config("singleuser.image.pullSecrets"):
image_pull_secrets.extend(get_config("singleuser.image.pullSecrets"))
if image_pull_secrets:
c.KubeSpawner.image_pull_secrets = image_pull_secrets
# scheduling:
if get_config("scheduling.userScheduler.enabled"):
c.KubeSpawner.scheduler_name = get_name("user-scheduler")
if get_config("scheduling.podPriority.enabled"):
c.KubeSpawner.priority_class_name = get_name("priority")
# add node-purpose affinity
match_node_purpose =
get_config("scheduling.userPods.nodeAffinity.matchNodePurpose")
if match_node_purpose:
node_selector = dict(
matchExpressions=[
dict(
key="hub.jupyter.org/node-purpose",
operator="In",
values=["user"],
)
],
)
if match_node_purpose == "prefer":
c.KubeSpawner.node_affinity_preferred.append(
dict(
weight=100,
preference=node_selector,
),
)
elif match_node_purpose == "require":
c.KubeSpawner.node_affinity_required.append(node_selector)
elif match_node_purpose == "ignore":
pass
else:
raise ValueError(
f"Unrecognized value for matchNodePurpose: {match_node_purpose}"
)
# Combine the common tolerations for user pods with singleuser tolerations
scheduling_user_pods_tolerations =
get_config("scheduling.userPods.tolerations", [])
singleuser_extra_tolerations = get_config("singleuser.extraTolerations", [])
tolerations = scheduling_user_pods_tolerations +
singleuser_extra_tolerations
if tolerations:
c.KubeSpawner.tolerations = tolerations
# Configure dynamically provisioning pvc
storage_type = get_config("singleuser.storage.type")
if storage_type == "dynamic":
pvc_name_template = get_config("singleuser.storage.dynamic.pvcNameTemplate")
if pvc_name_template:
c.KubeSpawner.pvc_name_template = pvc_name_template
volume_name_template = get_config("singleuser.storage.dynamic.volumeNameTemplate")
c.KubeSpawner.storage_pvc_ensure = True
set_config_if_not_none(
c.KubeSpawner, "storage_class", "singleuser.storage.dynamic.storageClass"
)
set_config_if_not_none(
c.KubeSpawner,
"storage_access_modes",
"singleuser.storage.dynamic.storageAccessModes",
)
set_config_if_not_none(
c.KubeSpawner, "storage_capacity", "singleuser.storage.capacity"
)
# Add volumes to singleuser pods
c.KubeSpawner.volumes = [
{
"name": volume_name_template,
"persistentVolumeClaim": {"claimName": "{pvc_name}"},
}
]
c.KubeSpawner.volume_mounts = [
{
"mountPath": get_config("singleuser.storage.homeMountPath"),
"name": volume_name_template,
"subPath": get_config("singleuser.storage.dynamic.subPath"),
}
]
elif storage_type == "static":
pvc_claim_name = get_config("singleuser.storage.static.pvcName")
c.KubeSpawner.volumes = [
{"name": "home", "persistentVolumeClaim": {"claimName": pvc_claim_name}}
]
c.KubeSpawner.volume_mounts = [
{
"mountPath": get_config("singleuser.storage.homeMountPath"),
"name": "home",
"subPath": get_config("singleuser.storage.static.subPath"),
}
]
# Inject singleuser.extraFiles as volumes and volumeMounts with data loaded
from
# the dedicated k8s Secret prepared to hold the extraFiles actual content.
extra_files = get_config("singleuser.extraFiles", {})
if extra_files:
volume = {
"name": "files",
}
items = []
for file_key, file_details in extra_files.items():
# Each item is a mapping of a key in the k8s Secret to a path in this
# abstract volume, the goal is to enable us to set the mode /
# permissions only though so we don't change the mapping.
item = {
"key": file_key,
"path": file_key,
}
if "mode" in file_details:
item["mode"] = file_details["mode"]
items.append(item)
volume["secret"] = {
"secretName": get_name("singleuser"),
"items": items,
}
c.KubeSpawner.volumes.append(volume)
volume_mounts = []
for file_key, file_details in extra_files.items():
volume_mounts.append(
{
"mountPath": file_details["mountPath"],
"subPath": file_key,
"name": "files",
}
)
c.KubeSpawner.volume_mounts.extend(volume_mounts)
# Inject extraVolumes / extraVolumeMounts
c.KubeSpawner.volumes.extend(get_config("singleuser.storage.extraVolumes",
[]))
c.KubeSpawner.volume_mounts.extend(
get_config("singleuser.storage.extraVolumeMounts", [])
)
c.JupyterHub.services = []
c.JupyterHub.load_roles = []
# jupyterhub-idle-culler's permissions are scoped to what it needs only, see
# https://github.com/jupyterhub/jupyterhub-idle-culler#permissions.
#
if get_config("cull.enabled", False):
jupyterhub_idle_culler_role = {
"name": "jupyterhub-idle-culler",
"scopes": [
"list:users",
"read:users:activity",
"read:servers",
"delete:servers",
# "admin:users", # dynamically added if --cull-users is passed
],
# assign the role to a jupyterhub service, so it gains these permissions
"services": ["jupyterhub-idle-culler"],
}
cull_cmd = ["python3", "-m", "jupyterhub_idle_culler"]
base_url = c.JupyterHub.get("base_url", "/")
cull_cmd.append("--url=http://localhost:8081" + url_path_join(base_url, "hub/api"))
cull_timeout = get_config("cull.timeout")
if cull_timeout:
cull_cmd.append(f"--timeout={cull_timeout}")
cull_every = get_config("cull.every")
if cull_every:
cull_cmd.append(f"--cull-every={cull_every}")
cull_concurrency = get_config("cull.concurrency")
if cull_concurrency:
cull_cmd.append(f"--concurrency={cull_concurrency}")
if get_config("cull.users"):
cull_cmd.append("--cull-users")
jupyterhub_idle_culler_role["scopes"].append("admin:users")
if not get_config("cull.adminUsers"):
cull_cmd.append("--cull-admin-users=false")
if get_config("cull.removeNamedServers"):
cull_cmd.append("--remove-named-servers")
cull_max_age = get_config("cull.maxAge")
if cull_max_age:
cull_cmd.append(f"--max-age={cull_max_age}")
c.JupyterHub.services.append(
{
"name": "jupyterhub-idle-culler",
"command": cull_cmd,
}
)
c.JupyterHub.load_roles.append(jupyterhub_idle_culler_role)
for key, service in get_config("hub.services", {}).items():
# c.JupyterHub.services is a list of dicts, but
# hub.services is a dict of dicts to make the config mergable
service.setdefault("name", key)
# As the api_token could be exposed in hub.existingSecret, we need to read
# it it from there or fall back to the chart managed k8s Secret's value.
service.pop("apiToken", None)
service["api_token"] = get_secret_value(f"hub.services.{key}.apiToken")
c.JupyterHub.services.append(service)
for key, role in get_config("hub.loadRoles", {}).items():
# c.JupyterHub.load_roles is a list of dicts, but
# hub.loadRoles is a dict of dicts to make the config mergable
role.setdefault("name", key)
c.JupyterHub.load_roles.append(role)
# respect explicit null command (distinct from unspecified)
# this avoids relying on KubeSpawner.cmd's default being None
_unspecified = object()
specified_cmd = get_config("singleuser.cmd", _unspecified)
if specified_cmd is not _unspecified:
c.Spawner.cmd = specified_cmd
set_config_if_not_none(c.Spawner, "default_url", "singleuser.defaultUrl")
# --- Option A: Profiles (prebuilt images)
------------------------------------
# Landing page inside the user container
# c.Spawner.default_url = "/lab" # or "/tree" if you prefer classic
Notebook c.JupyterHub.redirect_to_server = True c.JupyterHub.default_url =
'/lab' # If you need a dockerconfigjson pull secret instead of IRSA,
uncomment:
# c.KubeSpawner.image_pull_secrets = ["ecr-dockerconfigjson"]
# One profile per image. "slug" becomes the query param for one-click links.
c.KubeSpawner.profile_list = [
{
"display_name": "Test-Notebook",
"slug": "pydata-stable1",
"description": "Python data stack (numpy, pandas, matplotlib, sklearn)",
"kubespawner_override": {
"image": "image",
"cmd": ["jupyterhub-singleuser"],
"image_pull_policy": "IfNotPresent",
"cpu_limit": 2,
"mem_limit": "2G",
# optional: env, nodeSelector, tolerations, etc.
"environment": {"JUPYTER_ENABLE_LAB": "yes",},
},
},
{
"display_name": "Anothr-Test-Notebook",
"slug": "pydata-stable2",
"description": "Local image",
"kubespawner_override": {
"image": "image2",
"cmd": ["jupyterhub-singleuser"],
"image_pull_policy": "IfNotPresent",
"cpu_limit": 2,
"mem_limit": "2G",
"environment": {"JUPYTER_ENABLE_LAB": "yes",},
},
},
{
"display_name": "R Stats",
"slug": "r-stats",
"description": "R + tidyverse + IRkernel",
"kubespawner_override": {
"image": "image9",
"image_pull_policy": "IfNotPresent",
"cpu_limit": 2,
"mem_limit": "4G",
},
},
{
"display_name": "GPU PyTorch",
"slug": "pytorch-gpu",
"description": "PyTorch + CUDA (requires GPU nodes)",
"kubespawner_override": {
"image": "image10",
"image_pull_policy": "IfNotPresent",
"cpu_limit": 4,
"mem_limit": "16G",
"extra_resource_limits": {"nvidia.com/gpu": "1"},
},
},
]
Could you post a screenshot of the Hub home at /hub/home? Also you can set c.JupyterHub.default_url = '/hub/home' so you will be redirected to Hub home instead of your server directly.
Find my home page
Once I click on start server page below is the page.
If it does not work, it means most probably you are overriding the config somewhere later. Try setting it on Helm chart directly
https://test_url/hub/spawn/test?profile=pydata-stable
https://test_url/hub/spawn/test1?profile=pydata-stable1
can we able to access the url’s with different pods with single user
[D 2025-10-06 09:41:16.174 JupyterHub scopes:1010] Checking access to /hub/spawn/test via scope servers!server=test/
[W 2025-10-06 09:41:16.175 JupyterHub scopes:1019] Not authorizing access to /hub/spawn/test. Requires any of [servers] on server=test/, not derived from scopes [read:users:groups!user=sushma priya, delete:servers!user=sushma priya, users:activity!user=sushma priya, users:shares!user=sushma priya, read:users!user=sushma priya, read:shares!user=sushma priya, read:users:name!user=sushma priya, access:servers!user=sushma priya, read:servers!user=sushma priya, tokens!user=sushma priya, read:tokens!user=sushma priya, read:users:activity!user=sushma priya, read:users:shares!user=sushma priya, servers!user=sushma priya]
[W 2025-10-06 09:41:16.175 JupyterHub web:1873] 404 GET /hub/spawn/test?profile=pydata-stable (10.156.102.5): No access to resources or resources not found
[W 2025-10-06 09:41:16.178 JupyterHub log:192] 404 GET /hub/spawn/test?profile=pydata-stable (sushma priya@10.156.102.5) 14.80ms
[D 2025-10-06 09:41:16.537 JupyterHub log:192] 304 GET /hub/static/components/@fortawesome/fontawesome-free/webfonts/fa-solid-900.woff2 (@10.156.101.150) 1.54ms