Dear stv0g,
Need Help …
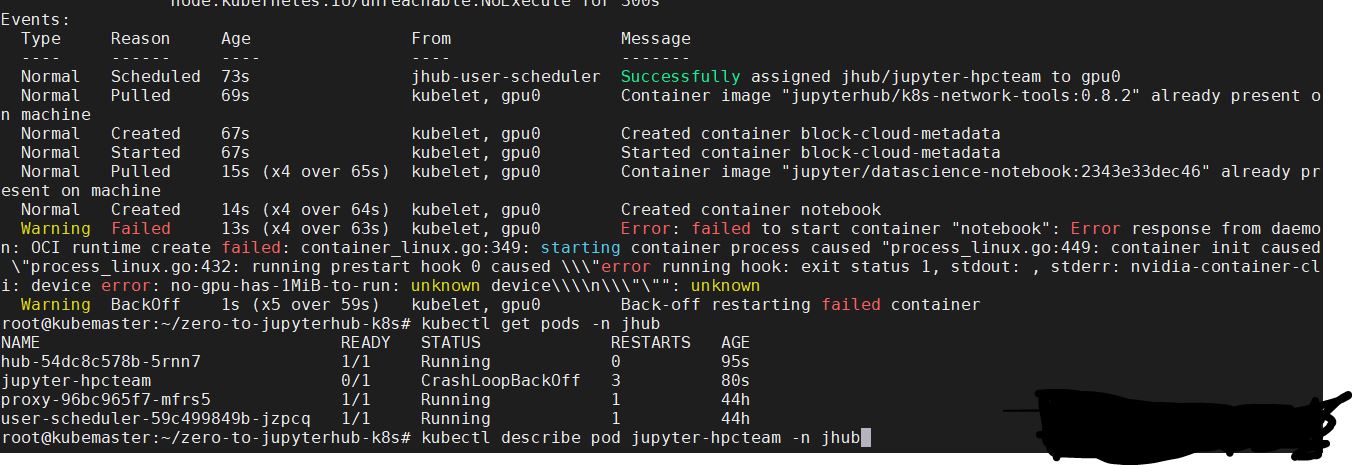
we are trying to use “gpushare-scheduler-extender” from Alibaba in our on-premise Z2JH cluster. Getting the following error.
“Error: failed to start container “notebook”: Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused “process_linux.go:449: container init caused “process_linux.go:432: running prestart hook 0 caused \“error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: device error: no-gpu-has-1MiB-to-run: unknown device\\n\”””: unknown”
configuration used in config.yaml: (snippet)
singleuser:
image:
name: jupyter/base-notebook
tag: 2343e33dec46
profileList:
- display_name: “Learning Data Science - with ONE GPU - shared 1GB”
description: “Datascience Environment with Sample Notebooks - with one gpu - shared 1GB”
kubespawner_override:
image: jupyter/datascience-notebook:2343e33dec46
extra_resource_limits:
# GiB
aliyun.com/gpu-mem: 1
Please kindly assist us to configure Z2JH to use “gpushare-scheduler-extender” from Alibaba in our on-premise cluster. can you share config.yaml syntax to configure Z2JH to use “aliyun.com/gpu-mem: 1” resource limit …
Thanks in advance …

 ![gpu_share_schedule_error|690x240]!
![gpu_share_schedule_error|690x240]!